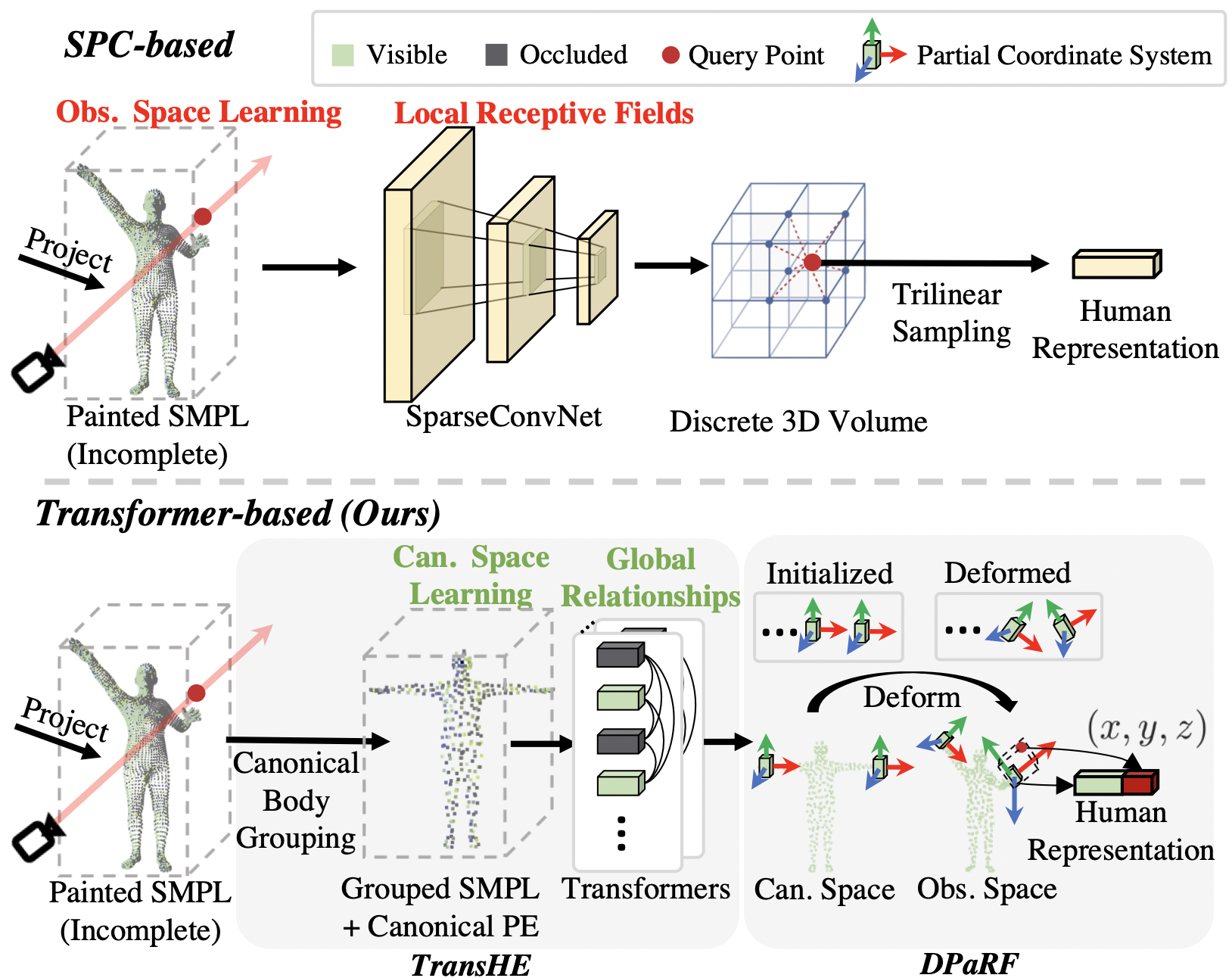
Previous methods have primarily used a SparseConvNet (SPC)-based human representation to process the painted SMPL. However, such SPC-based representation i) optimizes under the volatile observation space which leads to the pose-misalignment between training and inference stages, and ii) lacks the global relationships among human parts that is critical for handling the incomplete painted SMPL.
Tackling these issues, we present a brand-new framework named TransHuman, which learns the painted SMPL under the canonical space and captures the global relationships between human parts with transformers.
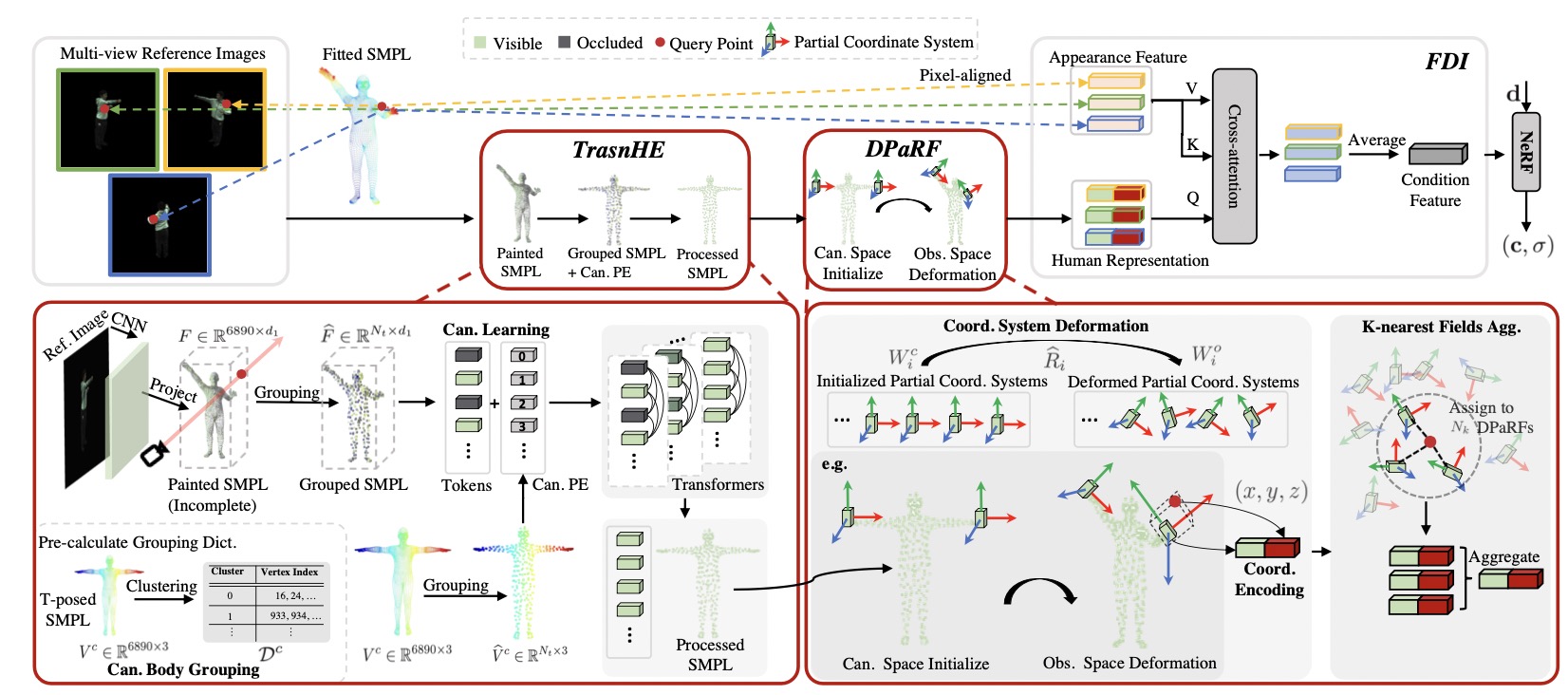
TransHuman is mainly composed of Transformer-based Human Encoding (TransHE), Deformable Partial Radiance Fields (DPaRF), and Fine-grained Detail Integration (FDI).
TransHE first builds a pipeline for capturing the global relationships between human parts via transformers under the canonical space.
Then, DPaRF deforms the coordinate system from the canonical back to the observation space and encodes a query point as an aggregation of coordinates and condition features.
Finally, FDI further gathers the fine-grained information of the observation space from the pixel-aligned appearance feature under the guidance of human representation.
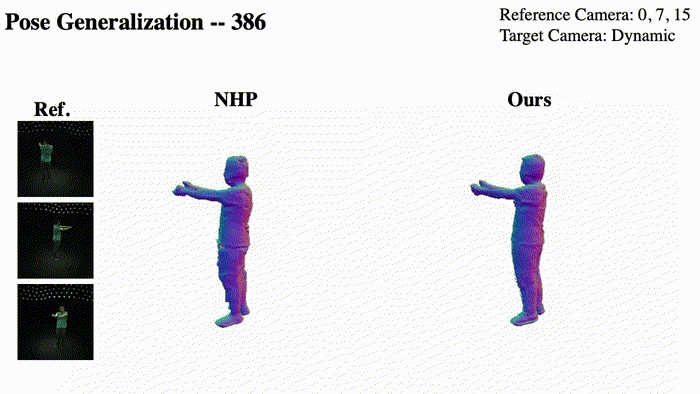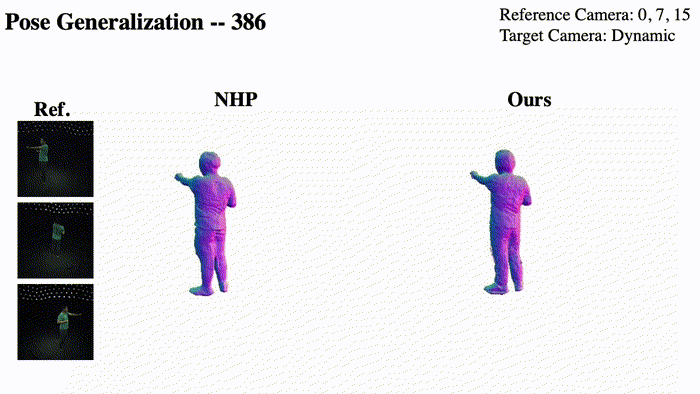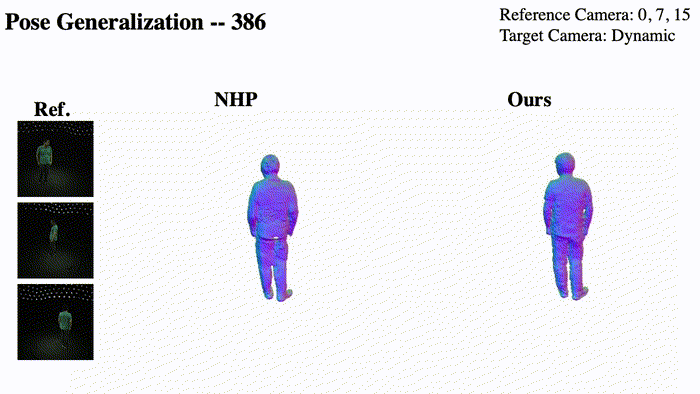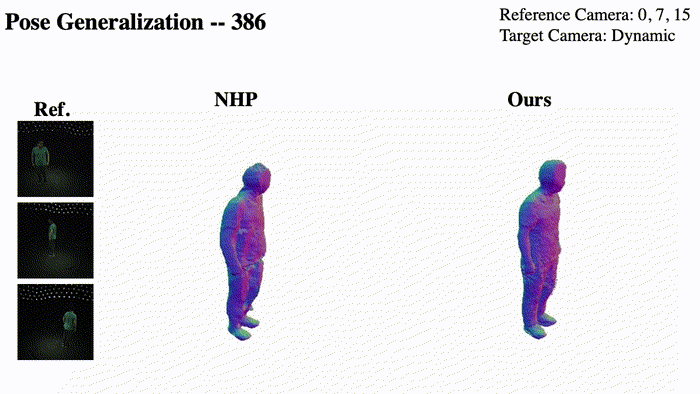
Please refer to our paper for more details.

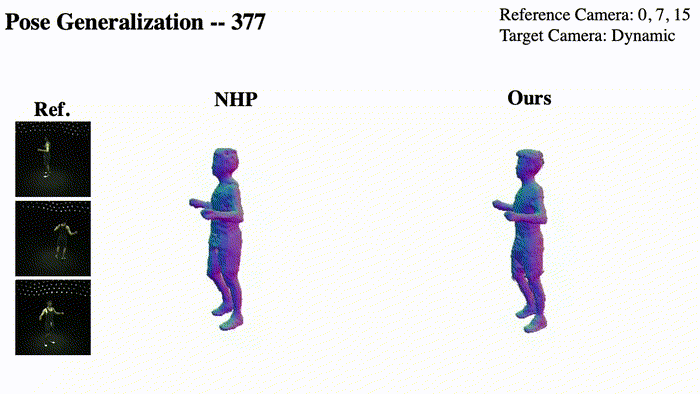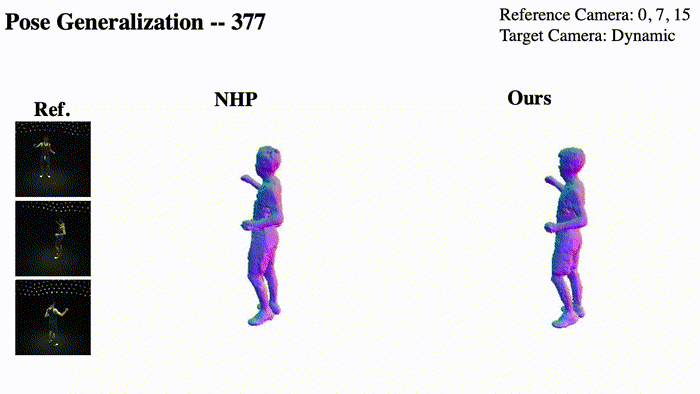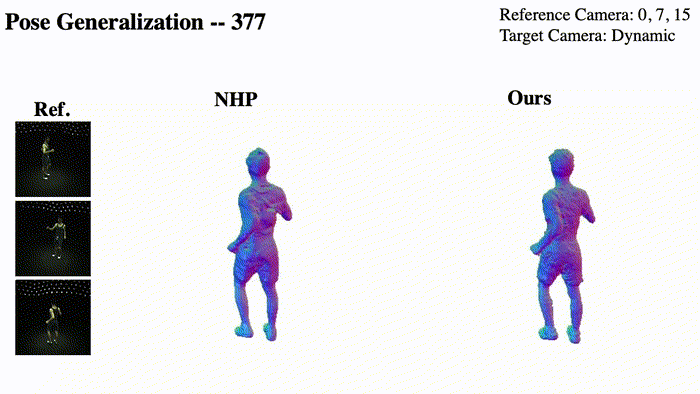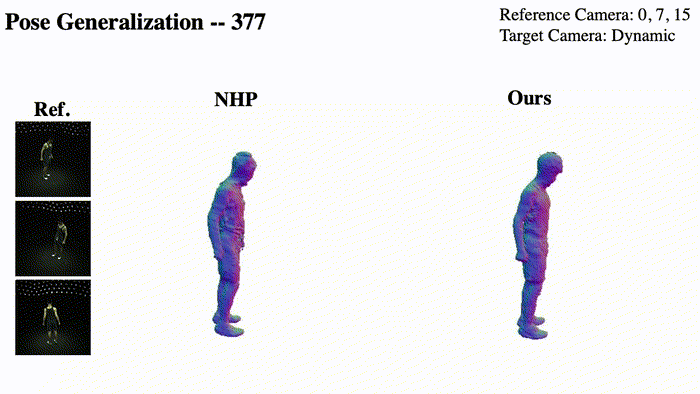



@InProceedings{Pan_2023_ICCV,
author = {Pan, Xiao and Yang, Zongxin and Ma, Jianxin and Zhou, Chang and Yang, Yi},
title = {TransHuman: A Transformer-based Human Representation for Generalizable Neural Human Rendering},
booktitle = {Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)},
month = {October},
year = {2023},
pages = {3544-3555}
}